Data Warehouse vs. Data Lake
Bei der Verwaltung und Analyse von Daten haben Anwender die Wahl zwischen zwei Ansätzen: dem riesigen Speicherpool für strukturierte und unstrukturierte Daten (Data Lake) und dem Data Warehouse – einer zentralisierten, strukturierten Datenbank. Beide Lösungen bringen Vor- und Nachteile mit sich und die Wahl hängt stark von den spezifischen Anforderungen und Zielen eines Unternehmens ab.

Wir werfen einen Blick auf beide Ansätze und helfen Ihnen bei der Einordnung.
Was ist ein Data Lake?
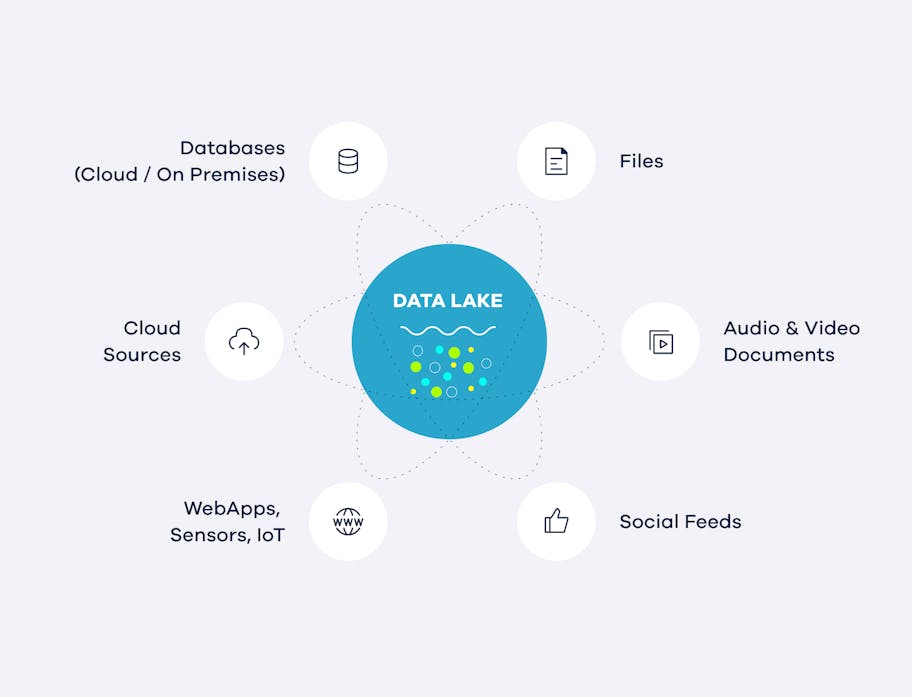
Die wichtigsten Vorteile eines Data Lakes
Skalierbarkeit
Ein Data Lake kann skaliert werden, um den Speicher- und Verarbeitungsbedarf eines Unternehmens zu bewältigen, was ihn zu einer guten Wahl für Unternehmen mit großen Datenmengen macht.
Kosteneffizienz
Es kann kostengünstiger sein als ein herkömmliches Data Warehouse.
Flexibilität
Ein Data Lake wird geschaffen, um Daten in ihrem Rohformat zu speichern. Das bedeutet, dass die Benutzer alle Informationen in den Daten behalten können, ohne befürchten zu müssen, dass einige von ihnen während des Umwandlungsprozesses verloren gehen.
Zugänglichkeit
Es die Speicherung und den Zugriff auf Daten aus verschiedenen Quellen.
Demokratisierung der Daten
Ein Data Lake steht jedem Nutzer frei zur Verfügung, nicht nur Datenwissenschaftlern und Analysten.
Echtzeit-Analysen
Es kann Analysen in Echtzeit ausführen. Unternehmen erlaubt dies, Entscheidungen auf der Grundlage der aktuellsten Daten zu treffen.
Verbesserte Datenverwaltung
Ein Data Lake kann zur Verbesserung der Data Governance beitragen, indem er ein zentrales Repository für Daten bereitstellt und es Organisationen und Unternehmen ermöglicht, Richtlinien für den Datenzugriff und die Datennutzung festzulegen.
Die Nachteile eines Data Lakes
- Komplexität: Die Einrichtung und Pflege kann komplex sein, insbesondere wenn die Daten aus verschiedenen Quellen und Typen integriert werden. Dies kann spezielle Fähigkeiten und Tools erfordern, und es kann zeitaufwendig sein, den Data Lake effektiv zu verwalten.
- Qualität: In Data Lakes können rohe, unstrukturierte Daten gespeichert werden, was bedeutet, dass die Qualität variieren kann. Dies kann es erschweren, den Daten zu vertrauen, und macht es schwieriger, genaue und zuverlässige Erkenntnisse zu gewinnen.
- Sicherheit: In Data Lakes können große Mengen an sensiblen Daten gespeichert werden, daher ist die Sicherheit von entscheidender Bedeutung. Es muss unbedingt sichergestellt werden, dass die Daten geschützt sind und der Zugriff kontrolliert wird, um unbefugten Zugriff oder Verstöße zu verhindern.
- Kosten: Die Einrichtung und Wartung von Data Lakes können teuer sein, insbesondere wenn Sie große Datenmengen speichern und verarbeiten müssen. Dies kann eine beträchtliche Investition sein, insbesondere für kleinere Unternehmen und Organisationen.
- Verwaltung: Die effektive Verwaltung und Steuerung von Data Lakes können eine Herausforderung darstellen, insbesondere wenn Sie Daten aus verschiedenen Quellen speichern und verarbeiten müssen. Dies kann spezielle Tools und Prozesse erfordern, um sicherzustellen, dass die Daten angemessen verwendet werden und den gesetzlichen Anforderungen entsprechen
Was ist ein Data Warehouse?
Ein Data Warehouse ist auch ein zentrales Sammelbecken für die Speicherung von Daten aus vielen Quellen. Es wird zur Unterstützung von Business-Intelligence-Aktivitäten wie Datenanalyse und Berichterstattung verwendet, indem es den Benutzern ermöglicht, Daten aus einer einzigen Quelle abzurufen und zu analysieren.
Ein Data Warehouse speichert strukturierte Daten, d.h. alle Daten müssen auf eine bestimmte Weise organisiert sein und einem bestimmten Schema folgen, z.B. Zeilen und Spalten in einer Tabelle. Das Schema für die Dateneingabe wird durch das Laden in das Data Warehouse definiert und kann sich von Warehouse zu Warehouse unterscheiden.
Ursprünglich war ein Data Warehouse dazu gedacht, schnelle Abfragen und Analysen von platzierten Daten zu unterstützen, die für reine Lesevorgänge erstellt wurden. Heute wird es in der Regel zur Unterstützung von Business-Intelligence-Aktivitäten verwendet, z. B. zur Erstellung von Berichten, Dashboards und Ad-hoc-Analysen.
Einer der Hauptvorteile eines Data Warehouses besteht darin, dass es den Benutzern ermöglicht, Daten aus einer einzigen Quelle abzurufen und zu analysieren. In gewisser Weise spart dieser Ansatz Zeit und Ressourcen, aber das Hauptziel ist es, sicherzustellen, dass die für die Analyse verwendeten Daten immer konsistent und genau sind.
Ein Data Warehouse ist darauf ausgelegt, schnelle Abfragen und Analysen von Daten zu unterstützen, und ist daher eine gute Wahl für Organisationen und Unternehmen, die komplexe Analysen auf Basis großer Datenmengen durchführen müssen.

Data Warehouse Vorteile
Verbesserte Datenorganisation
Ein Data Warehouse ermöglicht die Speicherung aller Daten an einem einzigen, zentralisierten Ort. Dies erleichterten die Organisation und Verwaltung von Daten und ermöglicht einen einfacheren Zugriff und eine leichtere Analyse von Daten aus verschiedenen Quellen.
Erhöhte Datensicherheit
Ein Data Warehouse verfügt in der Regel über robustere Sicherheitsmaßnahmen als andere Arten von Datensystemen. Dies kann dazu beitragen, sensible Daten zu schützen und sicherzustellen, dass nur befugte Benutzer Zugang zu ihnen haben.
Bessere Einblicke
Durch die Speicherung von Daten in einem Datenlager kann die Analyse der Daten mit Hilfe leistungsfähiger Tools und Techniken dazu beitragen, Erkenntnisse zu gewinnen, die bei der Betrachtung der Rohdaten vielleicht nicht sofort ersichtlich sind. Dies ist jedoch von entscheidender Bedeutung in Situationen, in denen Daten den Kern einiger Geschäftsentscheidungen bilden.
Verbesserte Datenqualität
Ein Data Warehouse kann dazu beitragen, die Qualität der Daten zu verbessern, indem es eine einzige Version der Daten bereitstellt und Fehler und Inkonsistenzen aufdeckt und korrigiert.
Größere Skalierbarkeit
Ein Data Warehouse ist für die Verarbeitung großer Datenmengen ausgelegt und kann bei wachsendem Datenbedarf skaliert werden. Dies kann besonders für Unternehmen und Organisationen wichtig sein, die viele Daten haben oder die erwarten, dass sie in Zukunft mehr Daten generieren werden.
Die Nachteile eines Data Warehouses
Datenlager können Unternehmen mit hochleistungsfähigen und skalierbaren Analysen unterstützen. Allerdings haben sie einige spezifische Herausforderungen wie:
- Unzureichende Datenflexibilität: Data Warehouses funktionieren hervorragend mit strukturierten Daten, haben aber Schwierigkeiten mit halbstrukturierten und unstrukturierten Daten.
- Hohe Implementierungs- und Wartungskosten: Data Warehouses sind in der Regel teuer in der Implementierung und Wartung.
Data Warehouses vs. Data Lakes: die wichtigsten Unterschiede
Die Debatte zwischen Data Lakes und Data Warehouses fühlt sich manchmal wie eine unendliche Geschichte an. Jedes Jahr sieht diese Debatte anders aus, da das Data Warehouse und der Data Lake ihre Aktualisierungen erhalten. Angesichts der Bedeutung von datengesteuerten Analysen, funktionsübergreifenden Datenteams und der Cloud entscheiden sich Unternehmen bei der Diskussion um Data Lakes und Data Warehouse für eine Lösung.
Es ist jedoch nicht schwer zu erkennen, dass sich ein Data Lake und ein Data Warhouse in einem Daten-Workflow gegenseitig ergänzen können.
Aber auch wenn wir denken, dass Data Warehouses und Data Lakes viele Unterschiede aufweisen - das tun sie nicht. Ein Hauptunterschied zwischen Data Warehouses und Data Lakes ist der Grad der Strukturierung der Daten.
In Data Warehouses werden in der Regel strukturierte Daten gespeichert, die auf vorhersehbare und konsistente Weise organisiert sind, während Data Lakes für die Speicherung unstrukturierter Daten konzipiert sind, die weniger organisiert sind und eine vielfältigere Struktur aufweisen können.
Das bedeutet, dass Data Lakes besser für die Speicherung großer Datenmengen aus einer Vielzahl von Quellen geeignet sind, einschließlich sozialer Medien, Sensoren und Weblogs, während Data Warehouses besser für die Speicherung und Analyse von strukturierten Daten aus Transaktionssystemen und anderen strukturierten Quellen geeignet sind.
Ein weiterer Unterschied ist die Art und Weise, wie auf die Daten zugegriffen wird und wie sie analysiert werden. In Datenlagern werden in der Regel SQL-basierte Abfrage- und Analysewerkzeuge verwendet, während Datenseen ein breiteres Spektrum an Werkzeugen und Technologien unterstützen können, darunter Stapelverarbeitung, Stream-Verarbeitung und interaktive Abfragen. Das macht Data Lakes flexibler und vielseitiger, bedeutet aber auch, dass sie mehr Aufwand bei der Einrichtung und Verwaltung erfordern.

Ein Hauptunterschied zwischen Date Warehouses und Data Lakes ist der Grad der Strukturierung der Daten.
Technologien
Technologien für Data Warehouses
Relationale Datenbank: Relationale Datenbanken wie Oracle und MySQL sind die gängigste Art der Datenlagertechnologie. Diese Systeme speichern Daten in Tabellen und verwenden SQL, um die Daten abzufragen und zu bearbeiten.
Spaltenbasierte Datenbank: Spaltenbasierte Datenbanken wie Amazon Redshift und Vertica speichern Daten in Spalten und nicht in Zeilen, was sie für Data Warehouse-Anwendungen effizienter machen kann.
Data Warehouse-Anwendungen: Data Warehouse-Anwendungen, wie IBM Netezza und Teradata, sind spezialisierte Hardware- und Softwaresysteme, die speziell für das Data Warehouse entwickelt wurden. Diese Systeme können für schnelle Abfragen und Analysen hoch optimiert werden.
Cloud-Data Warehouse: Cloudbasierte Data Warehouses, wie z. B. Amazon Redshift und Google BigQuery, sind Data Warehouses, die von Cloud-Anbietern gehostet und verwaltet werden. Diese Systeme können flexibler und skalierbarer sein als herkömmliche Data Warehouses, die vor Ort betrieben werden.
Datenvirtualisierung: Datenvirtualisierungstechnologien wie Denodo und Informatica ermöglichen den Zugriff auf und die Integration von Daten aus verschiedenen Quellen, ohne dass die Daten physisch verschoben oder repliziert werden müssen. Dies kann den Aufbau und die Pflege eines Data Warehouses erleichtern.
Technologien für Data Lakes
Hadoop: Hadoop ist ein Open-Source-Framework für die Speicherung und Verarbeitung großer Datenmengen. Es besteht aus einem verteilten Dateisystem (HDFS) zur Speicherung von Daten und einer Verarbeitungsmaschine (MapReduce) zur Verarbeitung der Daten.
Spark: Apache Spark ist eine Open-Source-Datenverarbeitungs-Engine für die Verarbeitung großer Datenmengen. Es ist schneller und flexibler als Hadoop und kann für eine Vielzahl von Datenverarbeitungsaufgaben verwendet werden, darunter Stapelverarbeitung, Stream-Verarbeitung und maschinelles Lernen.
Cloud-Speicher: Cloud-Speichersysteme wie Amazon S3 und Google Cloud Storage werden häufig zur Speicherung von Daten in Data Lakes verwendet. Diese Systeme sind hoch skalierbar und können große Datenmengen zu geringen Kosten speichern.
NoSQL-Datenbank: NoSQL-Datenbanken, wie MongoDB und Cassandra, sind für die Speicherung und Verarbeitung großer Mengen unstrukturierter Daten konzipiert. Sie werden häufig in Data Lakes verwendet, um Daten aus Quellen wie sozialen Medien, Weblogs und Sensoren zu speichern.
Stream-Verarbeitung: Stream-Processing-Technologien wie Apache Flink und Apache Beam werden verwendet, um Daten in Echtzeit zu verarbeiten, während sie in den Daten Lake eingespeist werden. Dies kann für Aufgaben wie die Datenbereinigung und -umwandlung sowie für die Erkennung von Mustern und Anomalien in den Daten nützlich sein.
Woher weiß man, ob ein Data Warehouse oder ein Data Lake für Ihr Unternehmen besser geeignet ist?
Bei der Entscheidung, ob ein Data Warehouse oder ein Data Lake für Ihr Unternehmen besser geeignet ist, sind einige Faktoren zu berücksichtigen:
- Datenquellen: Wenn Sie über eine große Anzahl unterschiedlicher Datenquellen verfügen, z. B. soziale Medien, Weblogs und Sensoren, ist ein Data Lake möglicherweise die bessere Lösung. Data Lakes sind für die Speicherung und Verarbeitung großer Mengen unstrukturierter Daten aus einer Vielzahl von Quellen konzipiert.
- Die Datenstruktur: Wenn Sie strukturierte Daten haben, z. B. Daten aus Transaktionssystemen und anderen strukturierten Quellen, ist ein Data Warehouse möglicherweise die bessere Lösung. Datenlager sind für die Speicherung und Analyse strukturierter Daten konzipiert.
- Datenvolumen: Wenn Sie große Datenmengen haben, ist ein Data Lake möglicherweise die bessere Lösung. Data Lakes sind für die Speicherung und Verarbeitung großer Datenmengen zu geringen Kosten konzipiert.
- Datenanalyse: Wenn Sie komplexe Analysen mit Ihren Daten durchführen müssen, z. B. maschinelles Lernen und prädiktive Modellierung, ist ein Data Lake möglicherweise die bessere Lösung. Data Lakes können eine breite Palette von Tools und Technologien für die Datenanalyse unterstützen.
- Geschäftliche Anforderungen: Berücksichtigen Sie Ihre geschäftlichen Anforderungen und wie Sie die Daten nutzen wollen. Wenn Sie Business Intelligence- und Berichtsaktivitäten unterstützen müssen, ist ein Data Warehouse möglicherweise die bessere Lösung. Wenn Sie Big-Data-Analysen und Data-Science-Projekte unterstützen, ist ein Data Lake möglicherweise die bevorzugte Lösung.
Sie haben noch Fragen?
Fragen Sie unseren Experten.


