Data Warehouse vs. Data Lake
When managing and analysing data, users have a choice between two approaches: the huge storage pool for structured and unstructured data (data lake) and the data warehouse – a centralised, structured database. Both solutions have advantages and disadvantages and the choice greatly depends on a company’s specific requirements and objectives.

We have taken a look at both approaches and will help you differentiate between them.
What is a data lake?
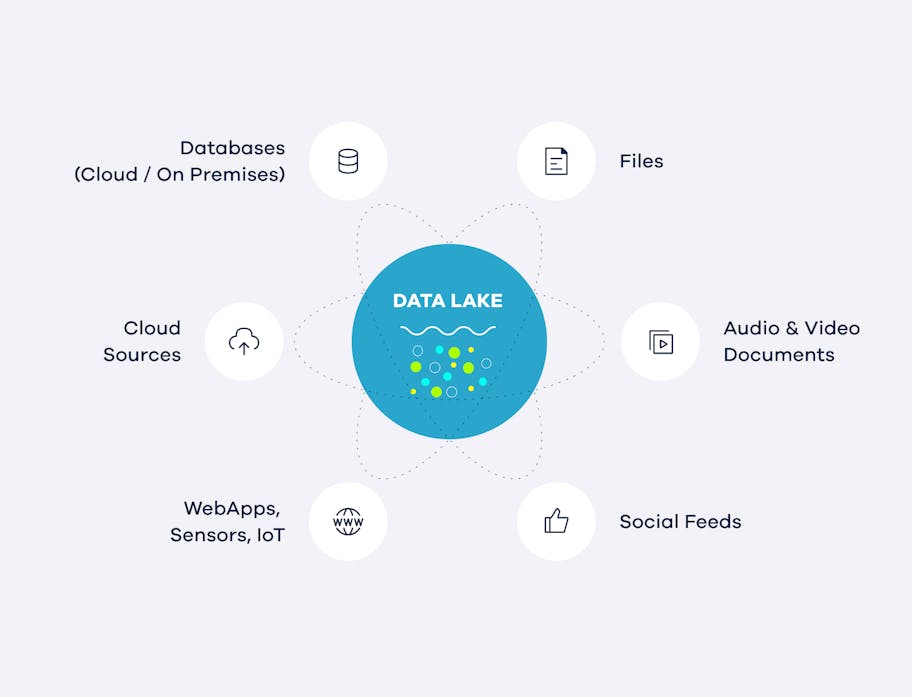
The key benefits of a data lake
Scalability
A data lake can be scaled to handle the specific storage and processing needs of an organisation, making it a good choice for organisations with large amounts of data.
Cost-efficiency
It can be more affordable than a conventional data warehouse.
Flexibility
A data lake is created to store data in its raw format. As a result, users can keep all the information in the data without fear of losing some of it during the transformation process.
Accessibility
It enables data to be stored and accessed from a variety of sources.
Democratisation of data
A data lake is freely available to any user, not just data scientists and analysts.
Real-time analysis
It can perform analyses in real time. This enables companies to make decisions based on the most up-to-date data.
Improved data management
A data lake can help improve data governance by providing a central repository for data and allowing organisations and businesses to set policies for data access and use.
The disadvantages of a data lake
- Complexity: Set-up and maintenance can be complex, especially when integrating data from different sources and types. It can require specialised skills and tools. And it can be time-consuming to manage the data lake effectively.
- Quality: Data lakes can store raw, unstructured data – which means that the quality can vary. This can make it difficult to have confidence in the data and makes it harder to gain accurate and reliable insights.
- Security: Data lakes can store large amounts of sensitive data, so security is paramount. It is essential to ensure that data is protected and access is controlled to prevent unauthorised access or breaches.
- Cost: Data lakes can be expensive to set up and maintain, especially if you need to store and process large amounts of data. This can represent a significant investment, especially for smaller businesses and organisations.
- Management: Effective management and control of data lakes can be challenging, especially if you need to store and process data from multiple sources. This can require specific tools and processes to ensure that data is used appropriately and complies with regulatory requirements.
What is a data warehouse?
A data warehouse is also a central repository for storing data from many sources. It is used to support business intelligence activities – such as data analysis and reporting – by enabling users to retrieve and analyse data from a single source.
A data warehouse stores structured data, which means that all data has to be organised in a certain way and follow a certain schema, e.g. rows and columns in a table. The schema for data entry is defined by loading it into the data warehouse and can differ from warehouse to warehouse.
Originally, a data warehouse was designed to support quick queries and analysis of placed data created for read-only operations. Today, it is typically used to support business intelligence activities, such as creating reports, dashboards and ad hoc analyses.
One of the main advantages of a data warehouse is that it allows users to retrieve and analyse data from a single source. In some ways, this approach saves time and resources, but the main goal is to ensure that the data used for analysis is always consistent and accurate.
A data warehouse is designed to support rapid queries and analysis of data and is a good choice for organisations and businesses that need to perform complex analysis based on large amounts of data.

Data warehouse benefits
Improved data organisation
A data warehouse allows all data to be stored in a single, centralised location. This facilitates the organisation and management of data and allows easier access and analysis of data from different sources.
Improved data security
Typically, a data warehouse has more robust security measures than other types of data systems. This can help protect sensitive data and ensure that only authorised users have access to it.
Better insights
By storing data in a data warehouse, analysing the data using powerful tools and techniques can help reveal insights that may not be immediately apparent when looking at the raw data. This can be crucial in situations where data is at the core of certain business decisions.
Improved data quality
A data warehouse can help improve the quality of data by providing a single version of the data, and detecting and correcting errors and inconsistencies.
Greater scalability
A data warehouse is designed to handle large amounts of data and can be scaled as data needs grow. This can be especially important for companies and organisations that have a lot of data or expect to generate more data in the future.
The disadvantages of a data warehouse
Data warehouses can support businesses with high-performance and scalable analyses. However, they do present certain challenges, such as:
- Insufficient data flexibility: Data warehouses work brilliantly with structured data, but have difficulties with semi-structured and unstructured data.
- High implementation and maintenance costs: Data warehouses are usually expensive to implement and maintain.
Data warehouses vs. data lakes: the main differences
The debate between data lakes and data warehouses sometimes feels interminable. Every year the debate looks different as the data warehouse and data lake receive their updates. Given the importance of data-driven analyses, cross-functional data teams and the cloud, companies are opting for one solution when debating data lakes and data warehouses.
However, it isn’t hard to see that a data lake and a data warehouse can complement each other in a data workflow.
But even if we think that data warehouses and data lakes have many differences – they really don’t. One main difference between data warehouses and data lakes is the degree to which the data is structured.
Data warehouses typically store structured data that is organised in a predictable and consistent manner, whereas data lakes are designed to store unstructured data that is less organised and can have a more varied structure.
This means that data lakes are better suited for storing large amounts of data from a variety of sources – including social media, sensors and weblogs – while data warehouses are better suited for storing and analysing structured data from transactional systems and other structured sources.
Another difference is how the data is accessed and analysed. Data warehouses typically use SQL-based query and analysis tools, while data lakes can support a wider range of tools and technologies, including batch processing, stream processing and interactive queries. This makes data lakes more flexible and versatile, but also means they require more effort to set up and manage.

A key difference between data warehouses and data lakes is the degree to which the data is structured.
Technologies
Technologies for data warehouses
Relational database: Relational databases such as Oracle and MySQL are the most common type of data storage technology. These systems store data in tables and use SQL to retrieve and manipulate the data.
Column-based database: Column-based databases such as Amazon Redshift and Vertica store data in columns rather than rows, which can make them more efficient for data warehouse applications.
Data warehouse applications: Data warehouse applications, such as IBM Netezza and Teradata, are specialised hardware and software systems designed specifically for the data warehouse. These systems can be highly optimised for fast queries and analysis.
Cloud data warehouse: Cloud-based data warehouses, such as Amazon Redshift and Google BigQuery, are data warehouses hosted and managed by cloud providers. These systems can be more flexible and scalable than traditional data warehouses that are run on-site.
Data virtualisation: Data virtualisation technologies such as Denodo and Informatica enable access to and integration of data from multiple sources without having to physically move or replicate the data. This can make it easier to build and maintain a data warehouse.
Technologies for data lakes
Hadoop: Hadoop is an open source framework for storing and processing large amounts of data. It consists of a distributed file system (HDFS) for storing data and a processing engine (MapReduce) for processing the data.
Spark: Apache Spark is an open source data processing engine for big data processing. It is faster and more flexible than Hadoop and can be used for a variety of data processing tasks, including batch processing, stream processing and machine learning.
Cloud storage: Cloud storage systems such as Amazon S3 and Google Cloud Storage are often used to store data in data lakes. These systems are highly scalable and can store large amounts of data at low cost.
NoSQL database: NoSQL databases, such as MongoDB and Cassandra, are designed to store and process large amounts of unstructured data. They are often used in data lakes to store data from sources such as social media, weblogs and sensors.
Stream processing: Stream processing technologies such as Apache Flink and Apache Beam are used to process data in real time as it is fed into the data lake. This can be useful for tasks such as data cleansing and transformation, and for detecting patterns and anomalies in the data.
How do you know if a data warehouse or a data lake is better suited for your company?
There are several factors to consider when determining whether a data warehouse or a data lake is better suited for your business:
- Data sources: If you have a large number of different data sources – social media, weblogs and sensors – a data lake may be a better solution. Data lakes are designed to store and process large amounts of unstructured data from a variety of sources.
- Data structure: If you have structured data – data from transactional systems and other structured sources – a data warehouse may be a better solution. Data warehouses are designed to store and analyse structured data.
- Data volume: If you have large amounts of data, a data lake may be a better solution. Data lakes are designed for storing and processing large volumes of data at low cost.
- Data analysis: If you need to perform complex analysis on your data, such as machine learning and predictive modelling, a data lake may be a better solution. Data lakes can support a wide range of tools and technologies for data analysis.
- Business requirements: Consider your business needs and how you plan to use the data. If you need to support business intelligence and reporting activities, a data warehouse may be a better solution. If you support Big Data analytics and data science projects, a data lake may be the preferred solution.
Do you still have questions?
Ask our experts.